
Most AI discussions focus on which model to use. But for European SMEs, the more consequential question is where it runs. Cloud AI means speed, convenience, and access to the best models on the planet. Self-hosted means control, predictable costs, and the certainty that your data never leaves your building. Neither is universally right. But the default choice (cloud, because it's easiest) is not always the smart one.
This article gives you a concrete decision framework with five criteria, backed by current cost data and compliance realities, so you can make an informed choice instead of drifting into one.
The Core Tradeoff in One Sentence
Cloud AI trades control for convenience. Self-hosted AI trades convenience for control.
Everything else is details. But the details matter a lot when you're a 30-person engineering firm in Austria handling proprietary client designs, or a 15-person law practice in Germany processing confidential contracts. Let's get into them.
The Cost Reality (2026 Numbers)
Vague comparisons are useless. Here are real numbers.
Cloud AI Costs
Token-based API pricing in April 2026: GPT-4o costs $2.50 per million input tokens and $10 per million output tokens. Claude Sonnet runs $3/$15. Smaller models are far cheaper: GPT-4o mini at $0.15/$0.60, Mistral Small at roughly $0.20/$0.60.
The upside: no upfront investment. Pure operating expense. You pay for what you use, and if usage drops, costs drop with it. For companies with demand that fluctuates by 40% or more throughout the day, cloud saves roughly 30-45% versus maintaining on-premise capacity for peak loads.
The downside: costs are unpredictable at scale. A 20-person team on ChatGPT Team at $25/user/month is $6,000/year. Manageable. But an API integration doing 1,000 calls a day at 2,000 tokens each quickly reaches $1,500-$2,000/month, and that number only goes up as usage grows.
Self-Hosted Costs
The entry point is lower than most people expect. An NVIDIA RTX 5090 (32 GB VRAM, the new sweet spot for local inference) has an MSRP of around EUR 2,300 in Europe. The previous generation RTX 4090 (24 GB) goes for EUR 1,700-2,200. For heavier workloads, a used NVIDIA A100 (80 GB) runs EUR 5,000-12,000 on the secondary market.
Add electricity (an RTX 5090 draws about 575W under full load, roughly EUR 60-100/month), a server to put it in, and 2-4 hours/month of someone's time for maintenance. That's it. No per-token cost. Unlimited usage once the hardware is paid for.
A practical budget setup: a single RTX 5090 in a dedicated workstation, EUR 3,000-5,000 all in. That card handles smaller models (8B-14B parameters) well, think Llama 3.1 8B, Gemma 2 9B, or Qwen 2.5 14B. These are genuinely capable for summarization, drafting, translation, and classification.
For the more powerful open-source models like Mistral Small 4 or Llama 4 Scout (both 100B+ parameters), a single 32 GB card won't cut it. Even quantized to Q4, these models need 50-55 GB just for weights, plus additional memory for context and concurrency. The most cost-effective path here is a dual GPU setup (two RTX 5090s, EUR 5,000-7,000), which gives you 64 GB of combined VRAM, enough to run these models quantized with room for a reasonable context window.
And there's an option many overlook: Apple MacBook Pros and Mac Studios with M-series chips. The unified memory architecture means a MacBook Pro M4 Max with 128 GB of unified RAM can run a 70B-parameter model locally at good speed, no GPU server required. A Mac Studio M4 Ultra with 192 GB handles even larger models. If your team already uses Macs, the hardware you need for local AI might already be sitting on someone's desk. Just Ollama and a terminal.
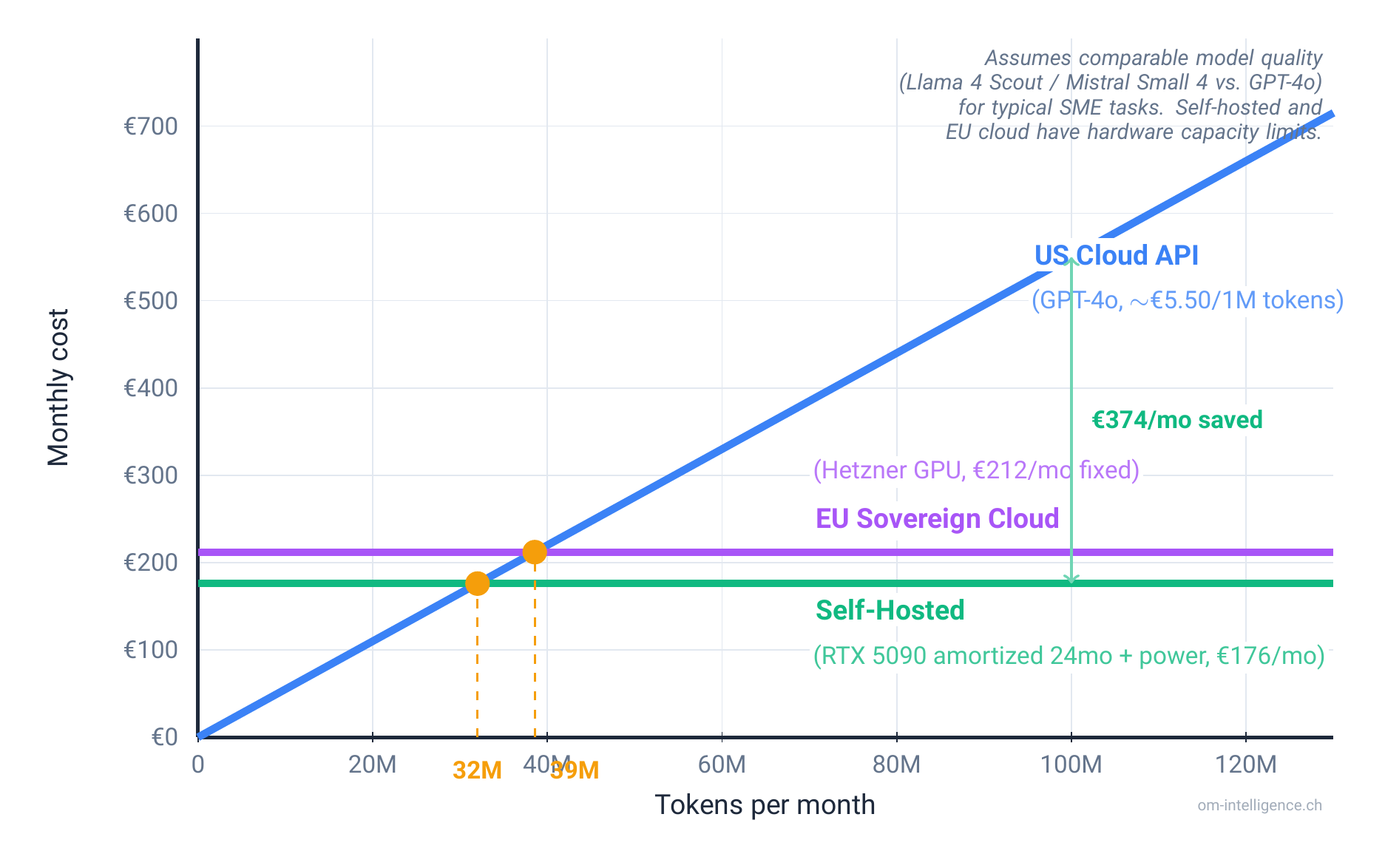
The Break-Even Math
This is where it gets interesting. The Lenovo Press 2026 analysis found that on-premise setups achieve breakeven in under 4 months for high-utilization workloads, with an 18x cost advantage per million tokens versus commercial API pricing.
More conservatively: if your team processes around 2 million tokens per day, self-hosting starts beating cloud APIs. At 5 million tokens/day on consumer hardware, you're looking at breakeven in 18-24 months. Below 100 million tokens per month, cloud is almost always cheaper.
The key variable is utilization. A GPU sitting idle 80% of the time is an expensive paperweight. Running at 60%+ utilization, self-hosted wins on cost within a year.
The Latency Reality
Cost is only half the equation. The other half is speed, and here the picture is more nuanced than "cloud is faster."
For a single user, self-hosted can actually be faster. An RTX 5090 generates around 213 tokens per second on an 8B model, and even the older RTX 4090 manages 128 tokens/second. That's faster than most cloud API streaming responses for a single request. You skip network round trips entirely.
The problem is concurrency. Cloud APIs serve requests across massive GPU clusters in parallel. Twenty people can query simultaneously and each gets a fast response. A single self-hosted GPU processes requests sequentially (or batches them with degraded per-user speed). If 15 employees share one RTX 5090, someone is waiting in a queue. With a 24B model, expect noticeable slowdowns beyond 3-5 concurrent users on a single consumer GPU.
The practical implication: self-hosting works well for small teams (under 10 active AI users) or for asynchronous workloads (batch processing documents overnight, for instance). For larger teams with bursty, concurrent usage, you either need multiple GPUs, an EU cloud provider, or a hybrid setup where the cloud handles peak demand. Don't size your self-hosted setup for average load; size it for the moment when everyone needs it at once.
The Compliance Factor
This is where the decision gets uniquely European.
The CLOUD Act Problem
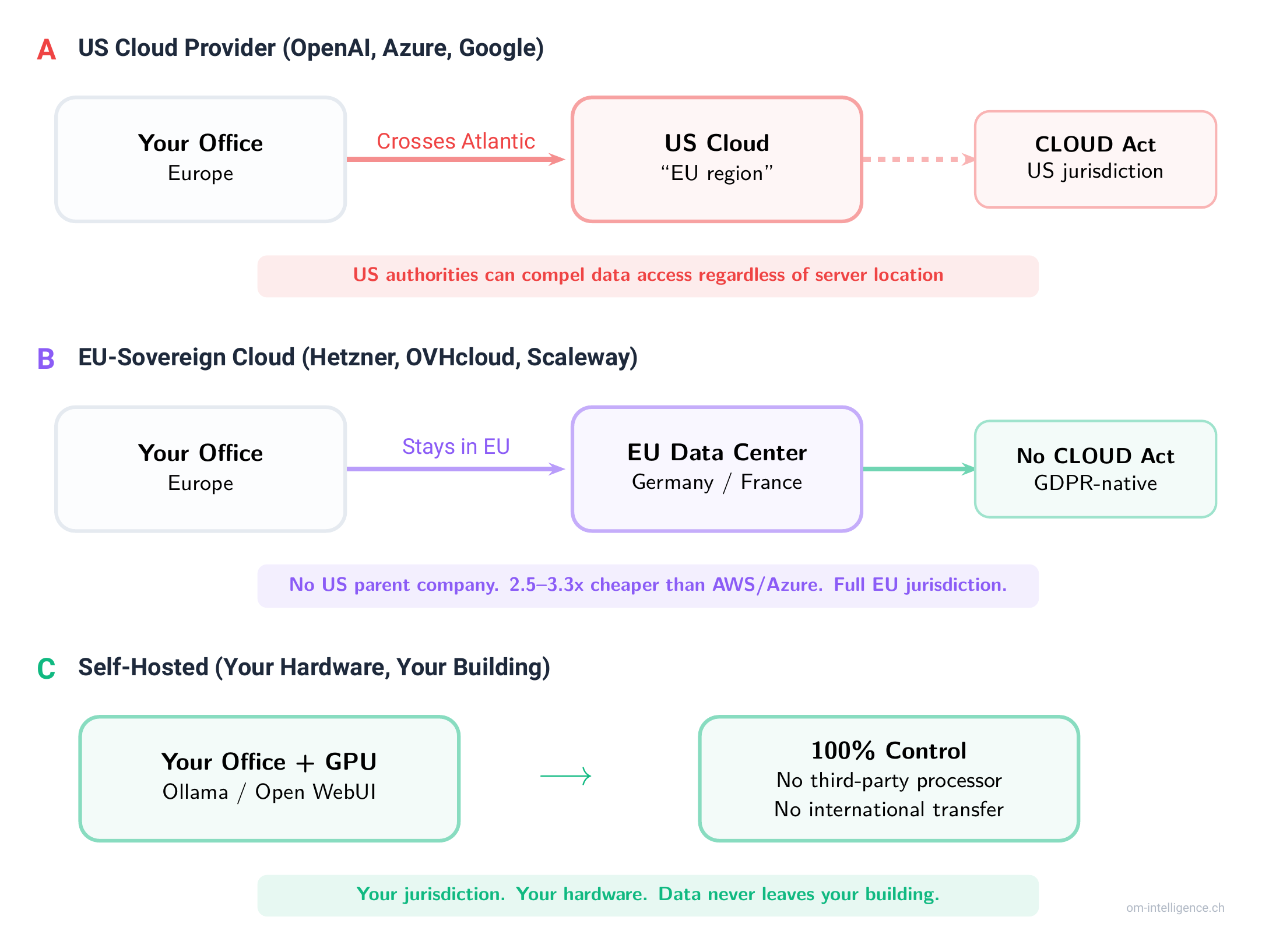
Every time you use a cloud AI service from a US provider (OpenAI, Anthropic, Google, Microsoft), your data is processed by a company subject to the US CLOUD Act. This 2018 law allows US law enforcement to compel American companies to hand over data stored anywhere in the world, regardless of where the server sits.
"But we use the EU data center region" is the most common objection we hear. It doesn't matter. The CLOUD Act applies to US-headquartered companies regardless of data center location. A Microsoft Azure server in Frankfurt is still Microsoft. An OpenAI API endpoint in the Netherlands is still OpenAI. The legal jurisdiction follows the company, not the hardware.
The EU-US Data Privacy Framework (the successor to Privacy Shield, which was struck down by the CJEU in Schrems II) is currently in place but faces a third legal challenge. If it falls again, the legal basis for sending data to US cloud providers collapses overnight, just as it did in 2020.
Self-hosted AI eliminates this entire category of risk. Your data stays on your hardware, in your building, under your jurisdiction. Full stop.
GDPR Simplification
Using cloud AI with customer data requires a Data Processing Agreement, a Transfer Impact Assessment, and reliance on transfer mechanisms that have been struck down twice before. Self-hosted AI means no third-party data processor, no international transfer. The GDPR analysis goes from a 20-page legal exercise to a straightforward internal processing operation.
EU AI Act
Both deployment models must comply with the EU AI Act if the use case falls into a regulated category. But self-hosted gives you more control over documentation, logging, and audit trails, all of which are requirements for high-risk systems. As we covered in our post on responsible AI for SMEs, deployer obligations apply regardless of where the AI runs.
The Decision Matrix: Five Criteria
Here's the framework. For each criterion, a clear signal for when cloud wins versus when self-hosted wins.
1. Data Sensitivity
Cloud wins when: Your data is non-sensitive, publicly available, or already shared with third parties. Marketing copy, public-facing content, general research.
Self-hosted wins when: Your data includes personal information, trade secrets, client confidential material, or falls under sector-specific regulation. Think: patient records, legal contracts, financial data, engineering designs, HR files.
2. Usage Volume and Predictability
Cloud wins when: Usage is sporadic, hard to predict, or varies wildly by season. A marketing team that runs heavy campaigns quarterly but is quiet in between.
Self-hosted wins when: Usage is steady, daily, and predictable. A customer support team processing hundreds of requests per day. An engineering team running document analysis every morning. Consistent load means consistent savings.
3. Model Quality Requirements
Cloud wins when: You need frontier-level reasoning. Complex legal analysis, nuanced creative writing, multi-step problem solving where the gap between open-source and proprietary models is still noticeable.
Self-hosted wins when: 80% quality is enough. And for most day-to-day SME tasks, it is. Text drafting, summarization, translation, classification, email generation, internal Q&A. A local Mistral Small 4 or Llama 4 Scout is indistinguishable from GPT-4o for these workloads.
4. Technical Capacity
Cloud wins when: Nobody on your team is comfortable with Linux, Docker, or server administration. And you don't want to hire for it.
Self-hosted wins when: You have at least one person who can manage a server. Ollama has made the setup bar remarkably low (15 minutes to a working model), and Open WebUI gives you a ChatGPT-like interface for the whole team. But someone still needs to own updates, monitoring, and the occasional hiccup. Budget 2-4 hours per month.
5. Regulatory Exposure
Cloud wins when: You operate in a low-regulation environment with no personal data processing and no EU market exposure.
Self-hosted wins when: You're in healthcare, finance, legal, HR, or any sector with strict data handling rules. The compliance overhead of getting cloud AI right (DPA, TIA, Schrems risk, vendor audits) can end up costing more than the hardware to self-host.
Putting It Together
Not all criteria carry equal weight for every company. But here's a practical summary:
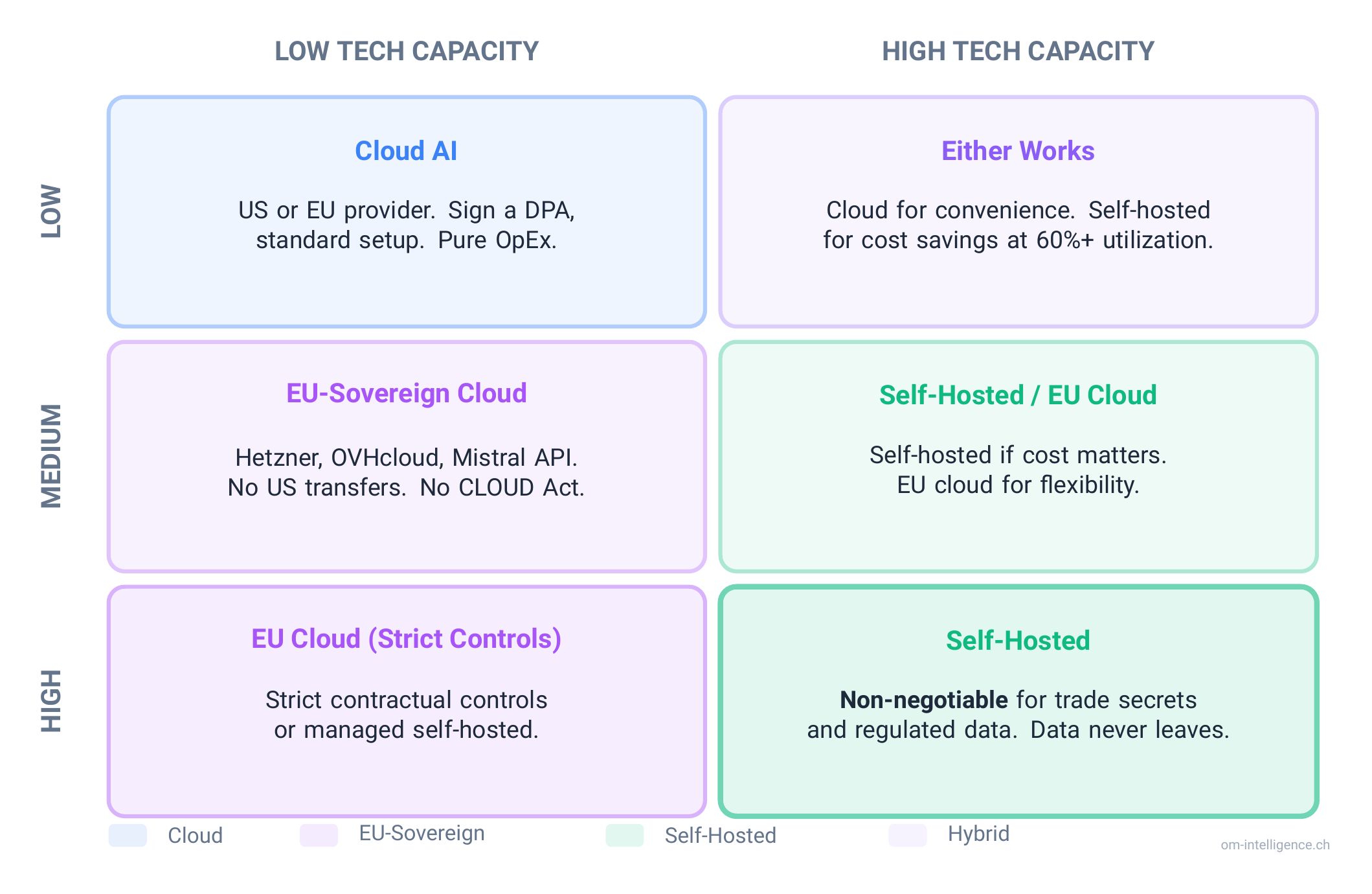
| Data Sensitivity | Technical Capacity | Recommended Approach |
|---|---|---|
| Low | Low | Cloud AI (US or EU provider). Sign a DPA, standard setup. |
| Low | High | Either works. Cloud for convenience, self-hosted for cost savings at scale. |
| Medium | Low | EU-sovereign cloud (Hetzner, OVHcloud, Mistral API). Avoid US transfers. |
| Medium | High | Self-hosted or EU-sovereign cloud. Self-hosted if cost matters. |
| High | Low | EU-sovereign cloud with strict contractual controls, or managed self-hosted. |
| High | High | Self-hosted. Non-negotiable for trade secrets and regulated data. |
The Third Option: EU-Sovereign Cloud
There's a middle path that many European SMEs overlook. European cloud providers like Hetzner, OVHcloud, Scaleway, and T-Systems are headquartered in Europe and offer GPU servers at a fraction of hyperscaler prices: Hetzner GPU servers start around EUR 212/month, roughly 2.5-3.3x cheaper than equivalent AWS or Azure capacity.
This gives you cloud convenience (no hardware to maintain, elastic scaling) with European jurisdiction and GDPR-native operations. For SMEs that need more than a single GPU but don't want to build a server room, this is often the sweet spot. One important nuance: some European providers (including Hetzner and OVHcloud) operate US subsidiaries, which creates a limited but real CLOUD Act nexus. The legal exposure is structurally far smaller than with US-headquartered providers, but it is not zero. We examine this in detail in our analysis of Hetzner US LLC and the CLOUD Act.
You can even run open-source models on EU cloud infrastructure, combining the cost advantage of models like Mistral Small 4 with the operational simplicity of cloud hosting. Best of both worlds, with none of the sovereignty headaches.
The Hybrid Path (What Most SMEs Should Actually Do)
For the majority of European SMEs, the answer is not pure cloud or pure self-hosted. It's a deliberate combination.
The Data Classification Approach
Classify your data into four categories: public, internal, confidential, restricted. Public and internal data can go to cloud AI with a standard DPA. Confidential and restricted data stays on self-hosted infrastructure. Simple rule, big impact. This captures most of the cost savings of self-hosting while maintaining cloud access for tasks that need it.
The Local-First, Cloud-Fallback Architecture
Route requests to a lightweight local model first. If the quality is good enough (and for 80% of day-to-day tasks, it will be), use that result. If not, escalate to a cloud-based frontier model. This pattern cuts costs on the majority of requests while maintaining access to top-tier quality when it actually matters.
What This Looks Like in Practice
Self-hosted component: Ollama on a dedicated machine (single RTX 5090 for smaller models, or a dual GPU setup for 100B+ models) for anything touching client data, internal documents, HR, or finance. EUR 3,000-7,000 one-time depending on configuration.
Cloud component: API access to GPT-4o or Claude for non-sensitive tasks requiring frontier quality: marketing copy, public content, research queries. Variable cost, typically EUR 200-500/month.
Routing: Start simple. A manual decision by the user: "Does this contain client data? Use the internal tool." As you get more comfortable, you can automate routing based on data classification.
Four SMEs, Four Decisions
These are composites, not client stories. But they reflect patterns we see regularly.
Law firm, 12 lawyers, Germany. Data: client contracts, legal research, correspondence. All highly confidential. One part-time IT person. Decision: self-hosted Qwen 2.5 14B on a single RTX 5090 workstation with Open WebUI for the team. More than capable for contract summarization, drafting, and translation. No data leaves the office network. Upfront cost: roughly EUR 4,000.
E-commerce company, 45 employees, Netherlands. Data: product descriptions, anonymized customer reviews, internal analytics. Mostly non-sensitive. Two-person IT team. Decision: Azure OpenAI Service (West Europe region) with DPA in place, plus ChatGPT Team for the content team. Cloud is the right call here.
Engineering consultancy, 28 engineers, Austria. Data: project specs, client technical documents, proprietary designs. Mixed sensitivity. One senior engineer comfortable with Linux. Decision: dual RTX 5090 workstation running Mistral Small 4 (quantized) for project work involving client data. Separate cloud account (no client data) for general research and brainstorming. Hybrid.
Medical device manufacturer, 80 employees, Switzerland. Data: R&D documents, regulatory submissions, HR records. Heavily regulated. Three-person IT team. Decision: on-premise GPU server (2x RTX 5090), Ollama + Open WebUI on an isolated network segment. No cloud AI for anything touching regulated data.
Three Mistakes to Avoid
1. Going all-cloud because it's the default. Convenience is not strategy. If you handle sensitive European data, the compliance overhead of cloud AI (DPA, TIA, vendor audits, Schrems risk) can end up costing more than the hardware to self-host. As we've argued before, sovereignty isn't just a value; it's a practical concern.
2. Going all-self-hosted to be "safe." Over-indexing on sovereignty at the expense of capability is also a mistake. If your team needs frontier-level reasoning and a cloud model solves it in seconds, the productivity gain matters. Don't let perfect sovereignty be the enemy of good outcomes.
3. Not deciding at all. This is the worst outcome. Employees pick whichever tool is easiest, paste client data into free-tier ChatGPT, use personal accounts for work tasks. No data classification, no documentation, no oversight. This creates the exact compliance risk you were trying to avoid, and you don't even know what data has gone where. As we explored in our post on responsible AI, the companies with the biggest exposure are the ones who never made an active decision.
Your Next Step
Audit your current AI usage this week. Open a spreadsheet and list every AI tool your company uses: who uses it, what data it touches, and where that data goes. Then map each use case against the five criteria above. The right architecture will become obvious.
You don't need to rip out your existing tools or buy a server tomorrow. You need a deliberate, documented decision about what goes where. Start there. Our AI Reality Checklist can help you structure that assessment, and it takes about 15 minutes.
Die meisten KI-Diskussionen drehen sich darum, welches Modell man verwenden soll. Aber für europäische KMU ist die folgenschwerere Frage: Wo läuft es? Cloud-KI bedeutet Geschwindigkeit, Komfort und Zugang zu den besten Modellen der Welt. Self-Hosting bedeutet Kontrolle, planbare Kosten und die Gewissheit, dass Ihre Daten Ihr Gebäude nie verlassen. Keines von beiden ist universell richtig. Aber die Standardwahl (Cloud, weil es am einfachsten ist) ist nicht immer die kluge.
Dieser Artikel gibt Ihnen einen konkreten Entscheidungsrahmen mit fünf Kriterien, gestützt auf aktuelle Kostendaten und Compliance-Realitäten, damit Sie eine informierte Wahl treffen können, statt in eine hineinzurutschen.
Der Kern-Tradeoff in einem Satz
Cloud-KI tauscht Kontrolle gegen Komfort. Self-Hosted-KI tauscht Komfort gegen Kontrolle.
Alles andere sind Details. Aber die Details zählen enorm, wenn Sie ein 30-Personen-Ingenieurbüro in Österreich sind, das proprietäre Kundendesigns bearbeitet, oder eine 15-Personen-Kanzlei in Deutschland, die vertrauliche Verträge verarbeitet.
Die Kostenrealität (Zahlen 2026)
Vage Vergleiche bringen nichts. Hier sind konkrete Zahlen.
Cloud-KI-Kosten
Token-basierte API-Preise im April 2026: GPT-4o kostet $2.50 pro Million Input-Tokens und $10 pro Million Output-Tokens. Claude Sonnet liegt bei $3/$15. Kleinere Modelle sind deutlich günstiger: GPT-4o mini bei $0.15/$0.60, Mistral Small bei etwa $0.20/$0.60.
Der Vorteil: keine Vorabinvestition. Reine Betriebsausgabe. Sie zahlen, was Sie nutzen, und wenn die Nutzung sinkt, sinken die Kosten mit. Für Unternehmen mit Nachfrageschwankungen von 40% oder mehr im Tagesverlauf spart Cloud rund 30-45% gegenüber der Vorhaltung von On-Premise-Kapazität für Spitzenlasten.
Der Nachteil: Kosten sind bei Skalierung schwer vorhersehbar. Ein 20-Personen-Team mit ChatGPT Team zu $25/Nutzer/Monat sind $6'000/Jahr. Machbar. Aber eine API-Integration mit 1'000 Aufrufen pro Tag bei durchschnittlich 2'000 Tokens erreicht schnell $1'500-$2'000/Monat, und diese Zahl steigt nur, wenn die Nutzung wächst.
Self-Hosted-Kosten
Der Einstiegspunkt ist niedriger, als die meisten erwarten. Eine NVIDIA RTX 5090 (32 GB VRAM, der neue Sweet Spot für lokale Inferenz) hat einen Richtpreis von rund EUR 2'300 in Europa. Die Vorgängergeneration RTX 4090 (24 GB) liegt bei EUR 1'700-2'200. Für schwerere Workloads geht eine gebrauchte NVIDIA A100 (80 GB) für EUR 5'000-12'000 auf dem Zweitmarkt.
Dazu kommen Strom (eine RTX 5090 zieht unter Volllast etwa 575W, rund EUR 60-100/Monat), ein Server und 2-4 Stunden/Monat für Wartung. Das war's. Keine Kosten pro Token. Unbegrenzte Nutzung, sobald die Hardware bezahlt ist.
Ein praktisches Budget-Setup: eine einzelne RTX 5090 in einer dedizierten Workstation, EUR 3'000-5'000 insgesamt. Diese Karte bewältigt kleinere Modelle (8B-14B Parameter) gut, etwa Llama 3.1 8B, Gemma 2 9B oder Qwen 2.5 14B. Diese sind für Zusammenfassungen, Texterstellung, Übersetzung und Klassifikation durchaus leistungsfähig.
Für die leistungsstärkeren Open-Source-Modelle wie Mistral Small 4 oder Llama 4 Scout (beide 100B+ Parameter) reicht eine einzelne 32-GB-Karte nicht aus. Selbst auf Q4 quantisiert benötigen diese Modelle 50-55 GB allein für die Gewichte, plus zusätzlichen Speicher für Kontext und Nebenläufigkeit. Der kosteneffizienteste Weg ist hier ein Dual-GPU-Setup (zwei RTX 5090, EUR 5'000-7'000), das 64 GB kombinierten VRAM bietet, genug um diese Modelle quantisiert mit ausreichendem Kontextfenster zu betreiben.
Und es gibt eine Option, die viele übersehen: Apple MacBook Pros und Mac Studios mit M-Serie-Chips. Dank der Unified-Memory-Architektur kann ein MacBook Pro M4 Max mit 128 GB RAM ein 70B-Parameter-Modell lokal in guter Geschwindigkeit ausführen, ganz ohne GPU-Server. Ein Mac Studio M4 Ultra mit 192 GB bewältigt noch grössere Modelle. Wenn Ihr Team bereits Macs nutzt, steht die Hardware für lokale KI möglicherweise schon auf jemandem seinem Schreibtisch. Nur Ollama und ein Terminal.
Die Break-Even-Rechnung
Hier wird es spannend. Die Lenovo Press 2026-Analyse zeigt, dass On-Premise-Setups bei hoher Auslastung den Break-Even in unter 4 Monaten erreichen, mit einem 18-fachen Kostenvorteil pro Million Tokens gegenüber kommerziellen API-Preisen.
Konservativer gerechnet: Wenn Ihr Team rund 2 Millionen Tokens pro Tag verarbeitet, beginnt Self-Hosting, Cloud-APIs zu schlagen. Bei 5 Millionen Tokens/Tag auf Consumer-Hardware liegt der Break-Even bei 18-24 Monaten. Unter 100 Millionen Tokens pro Monat ist Cloud fast immer günstiger.
Die entscheidende Variable ist die Auslastung. Eine GPU, die 80% der Zeit im Leerlauf steht, ist teurer Briefbeschwerer. Bei 60%+ Auslastung gewinnt Self-Hosted innerhalb eines Jahres.
Die Latenz-Realität
Kosten sind nur die halbe Gleichung. Die andere Hälfte ist Geschwindigkeit, und hier ist das Bild differenzierter als "Cloud ist schneller."
Für einen einzelnen Nutzer kann Self-Hosted tatsächlich schneller sein. Eine RTX 5090 generiert rund 213 Tokens pro Sekunde bei einem 8B-Modell, und selbst die ältere RTX 4090 schafft 128 Tokens/Sekunde. Das ist schneller als die meisten Cloud-API-Streaming-Antworten bei einer einzelnen Anfrage. Netzwerk-Latenzen entfallen komplett.
Das Problem ist Gleichzeitigkeit. Cloud-APIs verarbeiten Anfragen über massive GPU-Cluster parallel. Zwanzig Personen können gleichzeitig anfragen und jeder bekommt eine schnelle Antwort. Eine einzelne Self-Hosted-GPU verarbeitet Anfragen sequenziell (oder batchweise mit reduzierter Geschwindigkeit pro Nutzer). Wenn 15 Mitarbeitende eine RTX 5090 teilen, wartet jemand in der Schlange. Bei einem 24B-Modell sind spürbare Verlangsamungen ab 3-5 gleichzeitigen Nutzern auf einer einzelnen Consumer-GPU zu erwarten.
Die praktische Konsequenz: Self-Hosting funktioniert gut für kleine Teams (unter 10 aktive KI-Nutzer) oder für asynchrone Workloads (z.B. Stapelverarbeitung von Dokumenten über Nacht). Für grössere Teams mit ungleichmässiger, gleichzeitiger Nutzung brauchen Sie entweder mehrere GPUs, einen EU-Cloud-Anbieter oder ein Hybrid-Setup, bei dem die Cloud Spitzenlast abfängt. Dimensionieren Sie Ihr Self-Hosted-Setup nicht für die Durchschnittslast, sondern für den Moment, in dem alle es gleichzeitig brauchen.
Der Compliance-Faktor
Hier wird die Entscheidung spezifisch europäisch.
Das CLOUD-Act-Problem
Jedes Mal, wenn Sie einen Cloud-KI-Dienst eines US-Anbieters nutzen (OpenAI, Anthropic, Google, Microsoft), werden Ihre Daten von einem Unternehmen verarbeitet, das dem US CLOUD Act unterliegt. Dieses Gesetz von 2018 erlaubt es US-Strafverfolgungsbehörden, amerikanische Unternehmen zur Herausgabe von Daten zu zwingen, die überall auf der Welt gespeichert sind, unabhängig vom Standort des Servers.
"Aber wir nutzen die EU-Rechenzentrumsregion" ist der häufigste Einwand, den wir hören. Es spielt keine Rolle. Der CLOUD Act gilt für US-Unternehmen unabhängig vom Rechenzentrumsstandort. Ein Microsoft-Azure-Server in Frankfurt ist immer noch Microsoft. Ein OpenAI-API-Endpunkt in den Niederlanden ist immer noch OpenAI. Die Rechtsprechung folgt dem Unternehmen, nicht der Hardware.
Das EU-US Data Privacy Framework (der Nachfolger des Privacy Shield, das vom EuGH in Schrems II aufgehoben wurde) gilt derzeit, steht aber vor einer dritten rechtlichen Anfechtung. Fällt es erneut, bricht die Rechtsgrundlage für den Datentransfer zu US-Cloud-Anbietern über Nacht zusammen, genau wie 2020.
Self-Hosted-KI eliminiert diese gesamte Risikokategorie. Ihre Daten bleiben auf Ihrer Hardware, in Ihrem Gebäude, unter Ihrer Rechtsprechung. Punkt.
DSGVO-Vereinfachung
Cloud-KI mit Kundendaten erfordert einen Auftragsverarbeitungsvertrag, eine Transfer-Folgenabschätzung und die Stütze auf Transfermechanismen, die bereits zweimal gekippt wurden. Self-Hosted-KI bedeutet: kein externer Auftragsverarbeiter, kein internationaler Datentransfer. Die DSGVO-Analyse wird von einer 20-seitigen juristischen Übung zu einer unkomplizierten internen Verarbeitungsoperation.
EU AI Act
Beide Bereitstellungsmodelle müssen den EU AI Act einhalten, wenn der Anwendungsfall in eine regulierte Kategorie fällt. Aber Self-Hosted gibt Ihnen mehr Kontrolle über Dokumentation, Protokollierung und Audit-Trails, alles Anforderungen für Hochrisikosysteme. Wie wir in unserem Beitrag über verantwortungsvolle KI für KMU behandelt haben, gelten Deployer-Pflichten unabhängig davon, wo die KI läuft.
Die Entscheidungsmatrix: Fünf Kriterien
Hier ist das Framework. Für jedes Kriterium ein klares Signal, wann Cloud gewinnt und wann Self-Hosted.
1. Datensensibilität
Cloud gewinnt, wenn: Ihre Daten nicht sensibel, öffentlich verfügbar oder bereits mit Dritten geteilt sind. Marketing-Texte, öffentliche Inhalte, allgemeine Recherche.
Self-Hosted gewinnt, wenn: Ihre Daten personenbezogene Informationen, Geschäftsgeheimnisse, vertrauliches Kundenmaterial oder sektorspezifisch regulierte Daten enthalten. Beispiele: Patientenakten, Rechtsverträge, Finanzdaten, technische Zeichnungen, HR-Akten.
2. Nutzungsvolumen und Vorhersagbarkeit
Cloud gewinnt, wenn: Die Nutzung sporadisch, schwer vorhersagbar oder saisonal stark schwankend ist. Ein Marketing-Team, das quartalsweise intensive Kampagnen fährt, dazwischen aber ruhig ist.
Self-Hosted gewinnt, wenn: Die Nutzung stetig, täglich und vorhersagbar ist. Ein Support-Team, das Hunderte Anfragen pro Tag verarbeitet. Ein Engineering-Team, das jeden Morgen Dokumentenanalysen durchführt. Konstante Last bedeutet konstante Einsparungen.
3. Anforderungen an die Modellqualität
Cloud gewinnt, wenn: Sie Frontier-Level-Reasoning brauchen. Komplexe Rechtsanalysen, nuanciertes kreatives Schreiben, mehrstufige Problemlösung, bei der der Abstand zwischen Open-Source- und proprietären Modellen noch spürbar ist.
Self-Hosted gewinnt, wenn: 80% Qualität ausreicht. Und für die meisten alltäglichen KMU-Aufgaben ist das der Fall. Texterstellung, Zusammenfassung, Übersetzung, Klassifikation, E-Mail-Erstellung, internes Q&A. Ein lokales Mistral Small 4 oder Llama 4 Scout ist für diese Workloads nicht von GPT-4o zu unterscheiden.
4. Technische Kapazität
Cloud gewinnt, wenn: Niemand in Ihrem Team sich mit Linux, Docker oder Serveradministration auskennt. Und Sie dafür nicht einstellen wollen.
Self-Hosted gewinnt, wenn: Sie mindestens eine Person haben, die einen Server verwalten kann. Ollama hat die Einrichtungshürde bemerkenswert niedrig gemacht (15 Minuten bis zum funktionierenden Modell), und Open WebUI bietet dem ganzen Team eine ChatGPT-ähnliche Oberfläche. Aber jemand muss sich um Updates, Monitoring und gelegentliche Probleme kümmern. Rechnen Sie mit 2-4 Stunden pro Monat.
5. Regulatorische Exposition
Cloud gewinnt, wenn: Sie in einem wenig regulierten Umfeld ohne Verarbeitung personenbezogener Daten und ohne EU-Marktpräsenz operieren.
Self-Hosted gewinnt, wenn: Sie im Gesundheitswesen, Finanzsektor, Recht, HR oder einem anderen Sektor mit strengen Datenschutzregeln tätig sind. Der Compliance-Aufwand für Cloud-KI (AVV, TIA, Schrems-Risiko, Vendor-Audits) kann am Ende mehr kosten als die Hardware für Self-Hosting.
Zusammenfassung
Nicht alle Kriterien wiegen für jedes Unternehmen gleich schwer. Aber hier eine praktische Übersicht:
| Datensensibilität | Technische Kapazität | Empfohlener Ansatz |
|---|---|---|
| Niedrig | Niedrig | Cloud-KI (US- oder EU-Anbieter). AVV abschliessen, Standard-Setup. |
| Niedrig | Hoch | Beides möglich. Cloud für Komfort, Self-Hosted für Kosteneinsparungen bei Skalierung. |
| Mittel | Niedrig | EU-souveräne Cloud (Hetzner, OVHcloud, Mistral API). US-Transfers vermeiden. |
| Mittel | Hoch | Self-Hosted oder EU-souveräne Cloud. Self-Hosted, wenn Kosten zählen. |
| Hoch | Niedrig | EU-souveräne Cloud mit strengen Vertragskontrollen oder Managed Self-Hosted. |
| Hoch | Hoch | Self-Hosted. Nicht verhandelbar bei Geschäftsgeheimnissen und regulierten Daten. |
Die dritte Option: EU-souveräne Cloud
Es gibt einen Mittelweg, den viele europäische KMU übersehen. Europäische Cloud-Anbieter wie Hetzner, OVHcloud, Scaleway und T-Systems haben ihren Hauptsitz in Europa und bieten GPU-Server zu einem Bruchteil der Hyperscaler-Preise: Hetzner-GPU-Server ab rund EUR 212/Monat, etwa 2,5-3,3x günstiger als vergleichbare AWS- oder Azure-Kapazität.
Das gibt Ihnen Cloud-Komfort (keine Hardware-Wartung, elastische Skalierung) mit europäischer Jurisdiktion und DSGVO-nativen Abläufen. Für KMU, die mehr als eine einzelne GPU brauchen, aber keinen Serverraum bauen wollen, ist das oft der Sweet Spot. Eine wichtige Nuance: Einige europäische Anbieter (darunter Hetzner und OVHcloud) betreiben US-Tochtergesellschaften, was einen begrenzten, aber realen CLOUD-Act-Nexus schafft. Das rechtliche Risiko ist strukturell weit geringer als bei US-basierten Anbietern, aber es ist nicht null. Wir untersuchen dies im Detail in unserer Analyse von Hetzner US LLC und dem CLOUD Act.
Sie können sogar Open-Source-Modelle auf EU-Cloud-Infrastruktur betreiben und so den Kostenvorteil von Modellen wie Mistral Small 4 mit der betrieblichen Einfachheit von Cloud-Hosting kombinieren. Das Beste aus beiden Welten, ohne Souveränitätskopfschmerzen.
Der Hybrid-Weg (Was die meisten KMU tatsächlich tun sollten)
Für die Mehrheit der europäischen KMU lautet die Antwort nicht rein Cloud oder rein Self-Hosted. Es ist eine bewusste Kombination.
Der Datenklassifikations-Ansatz
Klassifizieren Sie Ihre Daten in vier Kategorien: öffentlich, intern, vertraulich, eingeschränkt. Öffentliche und interne Daten können mit Standard-AVV in die Cloud-KI. Vertrauliche und eingeschränkte Daten bleiben auf Self-Hosted-Infrastruktur. Einfache Regel, grosse Wirkung. So nutzen Sie den Grossteil der Kosteneinsparungen von Self-Hosting und behalten gleichzeitig Cloud-Zugang für Aufgaben, die ihn brauchen.
Local-First, Cloud-Fallback-Architektur
Leiten Sie Anfragen zuerst an ein lokales Modell. Wenn die Qualität ausreicht (und für 80% der täglichen Aufgaben wird sie das), nutzen Sie dieses Ergebnis. Wenn nicht, eskalieren Sie zu einem Cloud-basierten Frontier-Modell. Dieses Muster senkt die Kosten für die Mehrheit der Anfragen und behält Zugang zu Top-Qualität, wenn sie wirklich gebraucht wird.
Wie das in der Praxis aussieht
Self-Hosted-Komponente: Ollama auf einer dedizierten Maschine (einzelne RTX 5090 für kleinere Modelle, oder ein Dual-GPU-Setup für 100B+-Modelle) für alles, was Kundendaten, interne Dokumente, HR oder Finanzen berührt. EUR 3'000-7'000 einmalig je nach Konfiguration.
Cloud-Komponente: API-Zugang zu GPT-4o oder Claude für nicht-sensible Aufgaben, die Frontier-Qualität erfordern: Marketing-Texte, öffentliche Inhalte, Rechercheaufgaben. Variable Kosten, typischerweise EUR 200-500/Monat.
Routing: Starten Sie einfach. Eine manuelle Entscheidung des Nutzers: "Enthält das Kundendaten? Dann nutze das interne Tool." Mit zunehmender Erfahrung können Sie das Routing basierend auf Datenklassifikation automatisieren.
Vier KMU, vier Entscheidungen
Das sind zusammengesetzte Szenarien, keine Kundengeschichten. Aber sie spiegeln Muster wider, die wir regelmässig sehen.
Anwaltskanzlei, 12 Anwälte, Deutschland. Daten: Mandantenverträge, Rechtsrecherche, Korrespondenz. Alles streng vertraulich. Eine Teilzeit-IT-Person. Entscheidung: Self-Hosted Qwen 2.5 14B auf einer einzelnen RTX 5090-Workstation mit Open WebUI für das Team. Mehr als leistungsfähig genug für Vertragszusammenfassungen, Texterstellung und Übersetzung. Keine Daten verlassen das Büronetzwerk. Investition: rund EUR 4'000.
E-Commerce-Unternehmen, 45 Mitarbeitende, Niederlande. Daten: Produktbeschreibungen, anonymisierte Kundenbewertungen, interne Analysen. Grösstenteils nicht sensibel. Zwei-Personen-IT-Team. Entscheidung: Azure OpenAI Service (Region Westeuropa) mit AVV, plus ChatGPT Team für das Content-Team. Cloud ist hier die richtige Wahl.
Ingenieurberatung, 28 Ingenieure, Österreich. Daten: Projektspezifikationen, technische Kundendokumente, proprietäre Designs. Gemischte Sensibilität. Ein Senior-Ingenieur mit Linux-Erfahrung. Entscheidung: Dual-RTX-5090-Workstation mit Mistral Small 4 (quantisiert) für Projektarbeit mit Kundendaten. Separates Cloud-Konto (keine Kundendaten) für allgemeine Recherche und Brainstorming. Hybrid.
Medizintechnikhersteller, 80 Mitarbeitende, Schweiz. Daten: F&E-Dokumente, regulatorische Einreichungen, HR-Akten. Stark reguliert. Drei-Personen-IT-Team. Entscheidung: On-Premise-GPU-Server (2x RTX 5090), Ollama + Open WebUI auf einem isolierten Netzwerksegment. Keine Cloud-KI für regulierte Daten.
Drei Fehler, die Sie vermeiden sollten
1. Alles in die Cloud, weil es der Standard ist. Komfort ist keine Strategie. Wenn Sie sensible europäische Daten verarbeiten, kann der Compliance-Aufwand für Cloud-KI (AVV, TIA, Vendor-Audits, Schrems-Risiko) am Ende mehr kosten als die Hardware für Self-Hosting. Wie wir bereits argumentiert haben: Souveränität ist nicht nur ein Wert, sondern ein praktisches Anliegen.
2. Alles self-hosten, um "sicher" zu sein. Übertriebene Souveränität auf Kosten der Leistungsfähigkeit ist ebenfalls ein Fehler. Wenn Ihr Team Frontier-Level-Reasoning braucht und ein Cloud-Modell das in Sekunden löst, zählt der Produktivitätsgewinn. Lassen Sie nicht perfekte Souveränität zum Feind guter Ergebnisse werden.
3. Gar nicht entscheiden. Das ist das schlimmste Ergebnis. Mitarbeitende wählen, was am einfachsten ist, kopieren Kundendaten in die Gratisversion von ChatGPT, nutzen persönliche Accounts für Arbeitsaufgaben. Keine Datenklassifikation, keine Dokumentation, keine Aufsicht. Das erzeugt genau das Compliance-Risiko, das Sie vermeiden wollten, und Sie wissen nicht einmal, welche Daten wohin geflossen sind. Wie wir in unserem Beitrag über verantwortungsvolle KI dargelegt haben, haben die Unternehmen mit dem grössten Risiko diejenigen, die nie eine aktive Entscheidung getroffen haben.
Ihr nächster Schritt
Machen Sie diese Woche eine Bestandsaufnahme Ihrer aktuellen KI-Nutzung. Öffnen Sie eine Tabelle und listen Sie jedes KI-Tool auf, das Ihr Unternehmen nutzt: Wer nutzt es, welche Daten werden berührt und wohin gehen diese Daten? Dann ordnen Sie jeden Anwendungsfall den fünf Kriterien oben zu. Die richtige Architektur wird offensichtlich.
Sie müssen nicht sofort Ihre bestehenden Tools ablegen oder morgen einen Server kaufen. Sie brauchen eine bewusste, dokumentierte Entscheidung darüber, was wohin geht. Fangen Sie dort an. Unsere KI-Realitäts-Checkliste kann Ihnen helfen, diese Bestandsaufnahme zu strukturieren, und sie dauert etwa 15 Minuten.
Founder, OM Intelligence | MSc ETH Zürich